ENPH 353 - ROS + ML
Practicing:
- Machine Learning & AI: Training and deploying a CNN for imitation learning and sign detection.
- Computer Vision: Processing and analyzing images for autonomous navigation and obstacle avoidance.
- Robotics & Embedded Systems: Implementing a control system for an autonomous robot using ROS.
- Software Development: Writing and managing Python scripts for data collection, model training, and real-time execution.
- Data Collection & Processing: Labeling, filtering, and optimizing datasets to improve model accuracy.
- Optimization & Performance Tuning: Adjusting parameters, reducing model size, and optimizing real-time execution.
1. Background
Competition:
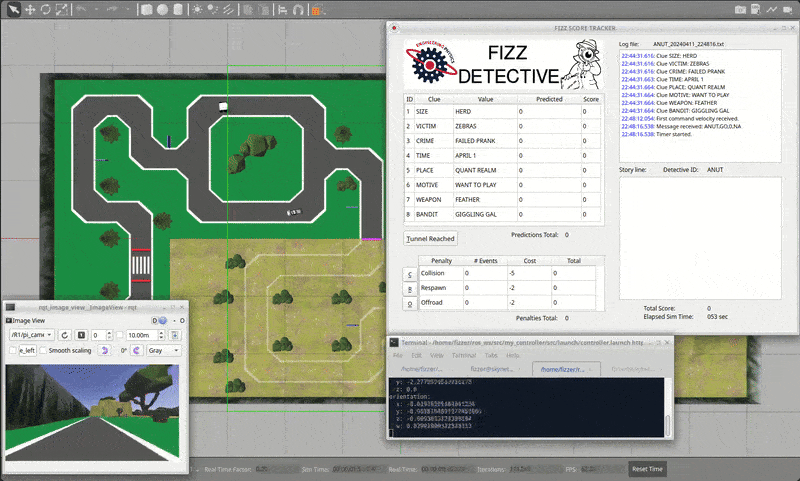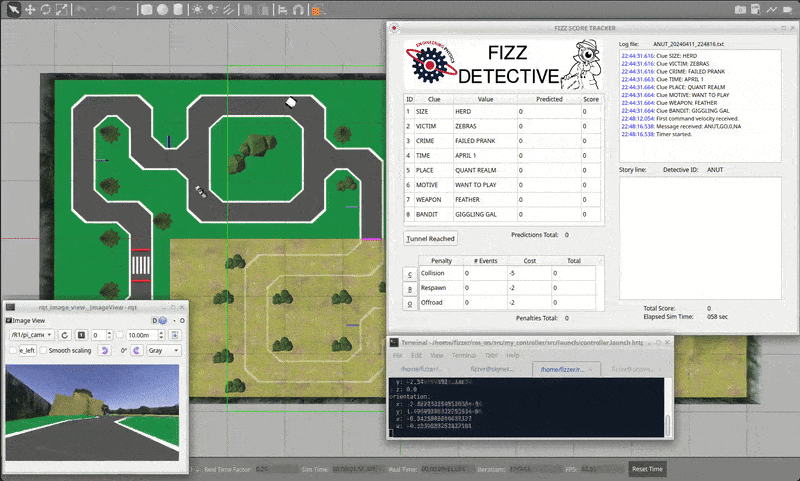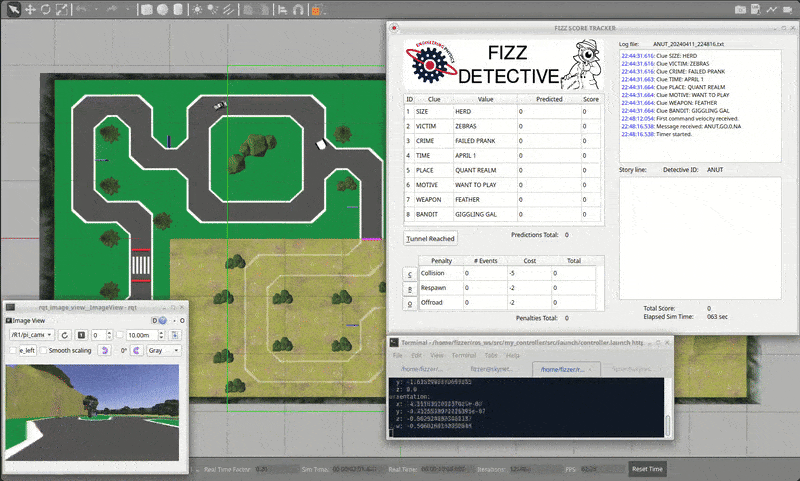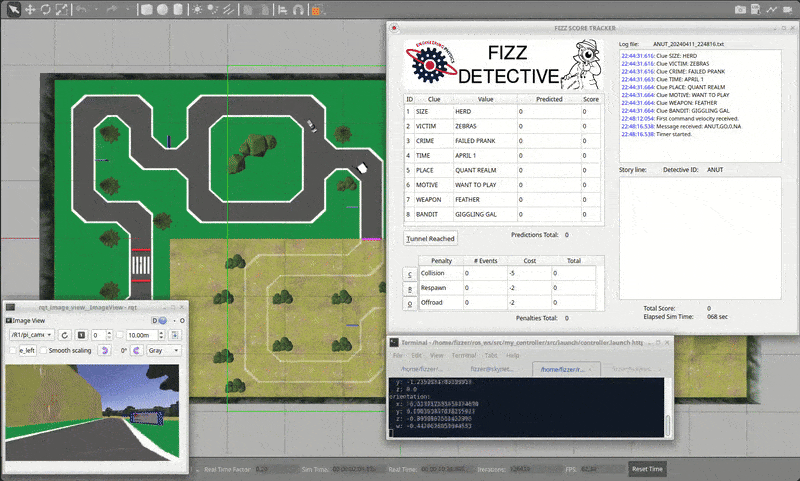
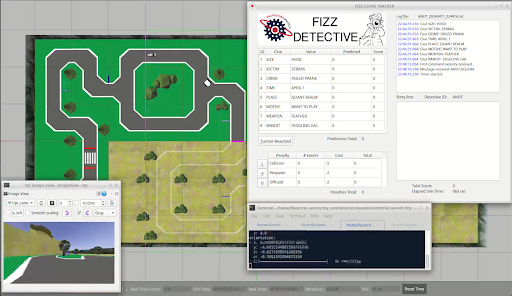
The theme for the competition is Fizz Detective. Our goal as a detective is to create an autonomous robot that can navigate a racetrack-like course all while finding clues for the mystery from reading signs placed throughout the track.
 |
|---|
| Figure 1: Competition track and Fizz Detective score tracker. |
In order to be the best detective, the robot must:
- Be able to drive around the whole course while staying on track and avoiding obstacles.
- Read the signs/clue boards located on the side of the roads.
Points are awarded for successfully reading the characters on the sign and getting past some certain hard-to-navigate areas of the track. One can also lose points by colliding with the pedestrian or moving car, and by going off track. The last important factor is time; if multiple teams achieve the maximum score, then whoever did it the fastest will win.
Our goals changed over the duration working up to the competition, which we were okay with. We were not worried about time, rather just focusing on being able to drive and read as many signs as we could, as we only had one attempt. Before the competition, we had a run of 30 points and we wanted to aim for that.
Contributions:
Trevor worked on the driving and training of a CNN using a custom dataset collected for imitation learning.
Anu worked on the clueboard detection and reading, accomplished by training a CNN using data that was collected from the clueboards themselves.
We ran the robot on Trevor’s laptop as Anu’s began to run out of memory and started to become unreliable approaching the competition date. We did notice that the performance of the combination of the driving and clue detection code did not perform well on Trevor’s computer, so we had to reduce the real-time factor (RTF) down from 1.0 to 0.2 to account for weak laptop performance.
Software Architecture:
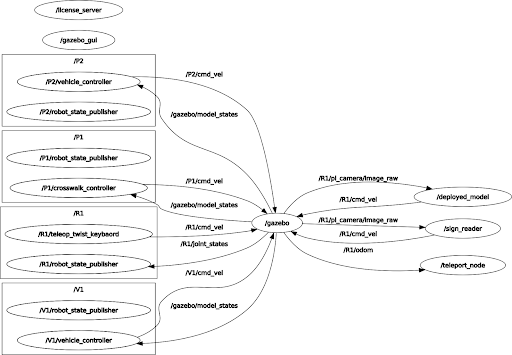
We have three nodes that were created, shown below on the right side of the graph: deployed_model, sign_reader, and teleport_node. The arrows leaving or entering their bubble represent listening and subscribing to topics.
 |
|---|
| Figure 2: ROS rqt_graph output. |
All of the images needed to drive and detect signs are received from /R1/pi_camera/image_raw camera topic. The /depolyed_model node loads the imitation learning model and publishes velocity commands to /R1/cmd_vel topic based on the images received. Similarly, /sign_reader node subscribes to the camera topic in order to read and process signs. Lastly, the /teleport_node node subscribes to the /R1/odom topic where we can look at the position and orientation of the robot in space, to help with respawning. These nodes and their interactions will be discussed in more detail in the following sections.
2. Driving System
Imitation Learning
Imitation learning was chosen due in part to the challenge, but also to take advantage of doing a machine learning course. Initially, this route made the most sense as a camera is already receiving images as input and one model could be made to run the whole course, making things relatively lightweight and simple. Through this process, data collection, image processing, and model parameter decisions will be discussed.
Data Collection
The first decision that needs to be made is what type of data will be collected, in other words, what should the robot imitate. Initially, it made sense to just keep moving forward until a turn needed to be made, in which the robot could stop and then pivot/turn in the correct direction; and that is what was done. The data_collector.py script was used to collect data; such that when the robot was controlled with teleop_twist_keyboard.py the keyboard velocity commands would determine the image’s label, which would be stored in its filename.
 |
 |
 |
| Figure 3: Raw images collected; labeled as: F_217.551, L_120.866, and R_52.667 respectively. | ||
Other data collection methods were explored that drastically altered the robot’s movement, the method described above was chosen because each of its actions is mapped to a single velocity command; keeping things simple.
Pre-processing
Since the raw images were saved from the data_collector.py script, freedom was gained to try many types of filtering/processing techniques; which significantly influenced the CNN’s size. The theme for processing was as little as possible.
 |
 |
 |
 |
| Figure 4: Comparison of raw images (top row) vs the same images without the top third (bottom row). | |
Now the only pre-processing of the frames that is done is to resize them to a fourth of their original size, convert values to float32, and normalize the image values so they are in the range of [0,1].
Model Creation
Architecture
The model is inspired by Bojarski et al. (2016) where a “convolutional neural network (CNN) [is used] to map raw pixels from a single front-facing camera directly to steering command.” The model is composed of four Conv2D layers doubling in filter size from 16 up to 128 in the same way as Bojarski et al. (2016); with a kernel size of 3x3.
Training Parameters and Validation
Instead of using the Adam optimizer, better results were found with RMSprop at a learning rate of 0.000075.
 |
|---|
| Figure 5: Output of model training. |
Tuning with DAgger Methods
When demonstrating the robot to Miti during office hours there were certain areas that were always problematic, such as certain turns. Miti then suggested exploring DAgger, a technique where the model would run, driving the robot (as intended), but whenever it approaches a problematic area an expert could take over.
 |
|---|
| Figure 6: Data collection breakdown. |
Obstacle Avoidance
Overall, the model itself seemed to inherit interesting solutions to obstacle avoidance that were not always intended. For example, the pedestrian crosswalk caused the robot to wiggle left and right as it centered itself in the road, then accelerated when the pedestrian left its view.